دانلود pdf یادگیری تقویتی کمیاب و عالی
یادگیری تقویتی یک حوزه مهم در هوش مصنوعی است که در آن عامل میآموزد چگونه در یک محیط خاص بهترین تصمیمات را اتخاذ کند.
این رویکرد به طور قابل توجهی با یادگیری با ناظر تفاوت دارد، جایی که عامل نیازی به دادههای برچسبدار قبلی ندارد.
در یادگیری با ناظر، سیستم از روی مجموعهای از نمونههای ورودی و خروجی صحیح آموزش میبیند تا الگوها را شناسایی کند.
اما در یادگیری تقویتی، عامل از طریق تعامل و آزمون و خطا با محیط، پاداشها را بهینه میکند.
نوع فایل: پی دی اف – 79 صفحه
فهرست مطالب:
- یادگیری تقویتی
- مقایسه RL با یادگیری با ناظر
- یادگیری با ناظر
- مشخصه های اصلی یادگیری تقویتی
- ساختار کلی مسئله یادگیری تقویتی
- محیط
- رفتار عامل
- پاداش
- در نظر گرفتن پاداشهای آینده
- مدلهای عملکرد بهینه
- خط مشی یا سیاست
- یادگیری خط مشی یا سیاست
- الگوریتم کلی یادگیری تقویتی
- مثال (مسئله میله و گاری)
- برخی کاربردهای برتر یادگیری تقویتی
- فرق پاداش و هدف
- خاصیت مارکف
- مثال (مسئله MDP با 16 حالت)
- تقریب تابع Value Function
- بدست آوردن سیاست بهینه
- استفاده از شبکه عصبی برای تخمین تابع مقدار
- الگوریتم یادگیری Q
- الگوریتم یادگیری Q برای MDP قطعی
- مثال (به روزرسانی مقادیر Q)
- اپیزودهای یادگیری
- اثبات همگرائی
- نحوه انجام آزمایش
- یادگیری Q برای MDP غیر قطعی
- الگوریتم (TD(λ
- ترکیب شبکه عصبی با یادگیری Q
- مسایل مطرح در یادگیری تقویتی
- سیستمهای بزرگ
- نتیجه گیری
قیمت: 55/500 تومان
مشخصههای اصلی یادگیری تقویتی شامل مفهوم پاداش، تعامل با محیط و هدف یادگیری یک سیاست بهینه است.
مطالب مرتبط
- دانلود pdf روانسنجی (روانشناسی) در 185 صفحه
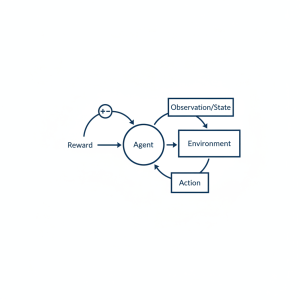
ساختار کلی مسئله یادگیری تقویتی همیشه شامل یک عامل و یک محیط در حال تعامل است. محیط، فضایی است که عامل در آن فعالیت میکند و بر اساس اقدامات عامل، بازخوردهایی را ارائه میدهد.
رفتار عامل نیز مجموعهای از تصمیمات و اعمال است که در هر حالت از محیط انجام میدهد. تابع تقویت (The Reinforcement Function) تعیینکننده پاداشهایی است که عامل در پاسخ به اقدامات خود دریافت میکند.
این پاداشها، اهرم اصلی یادگیری عامل هستند و در نظر گرفتن پاداشهای آینده برای دستیابی به اهداف بلندمدت بسیار حیاتی است. برای دستیابی به مدلهای عملکرد بهینه، عامل نیاز به توسعه یک خطمشی یا سیاست دارد که مشخص میکند در هر حالت چه عملی را باید انجام دهد.
یادگیری خطمشی یا سیاست فرآیند یافتن این استراتژی بهینه است. الگوریتم کلی یادگیری تقویتی شامل گامهای متوالی از مشاهده، اقدام، دریافت پاداش و بهروزرسانی سیاست است.
به عنوان مثال، در مسئله میله و گاری، عامل میآموزد که چگونه میله را در حالت تعادل نگه دارد. برخی کاربردهای برتر یادگیری تقویتی شامل رباتیک، بازیها، و سیستمهای توصیه است.
مهم است که فرق پاداش و هدف را درک کنیم؛ پاداش بازخورد فوری است، در حالی که هدف، حالت نهایی مطلوب است. برنامهنویسی پویا (Dynamic Programming) یک ابزار قدرتمند برای حل مسائل یادگیری تقویتی است، به خصوص در محیطهای با خاصیت مارکف.
خاصیت مارکف بیان میکند که حالت آینده فقط به حالت فعلی بستگی دارد، نه تاریخچه قبلی. فرآیندهای تصمیمگیری مارکف (MDPs) چارچوبی ریاضی برای مدلسازی مسائل یادگیری تقویتی فراهم میکنند.
مثالی از یک فرآیند تصمیمگیری مارکف متناهی میتواند حرکت یک ربات بازیافت (Recycling Robot MDP) باشد که تصمیمات آن بر اساس وضعیت فعلی انرژی و کارهایش است. برای درک بهتر، یک مثال از یادگیری تقویتی میتواند حل متاه (Maze) باشد که در آن عامل یاد میگیرد چگونه از نقطه شروع به نقطه پایان برسد.
عامل با انتخاب مسیرهای مختلف، پاداشهای مثبت و منفی دریافت میکند. تابع ارزش (Value Function) میزان مطلوبیت یک حالت یا یک جفت حالت-اقدام را در بلندمدت نشان میدهد.
تابع ارزش بهینه (The optimal value function) حداکثر ارزش قابل دستیابی را مشخص میکند و میتوان آن را با مثال تکرار ارزش (Value Iteration) محاسبه کرد. در بسیاری از موارد، باید تابع ارزش را تقریب زد (Approximating the Value Function)، به خصوص در محیطهای با حالتهای بسیار زیاد.
جوهر برنامهنویسی پویا بر مبنای حل زیرمسائل و استفاده از معادله بلمن (Bellman equation) برای یافتن راهحل بهینه است. تقریب تابع ارزش (Value Function) اغلب با استفاده از توابع تقریبی خطی یا غیرخطی انجام میشود.
برای به دست آوردن سیاست بهینه، میتوان از الگوریتمهای مختلفی مانند الگوریتمهای گرادیان باقیمانده (Residual Gradient Algorithms) استفاده کرد. استفاده از شبکه عصبی برای تخمین تابع مقدار یکی از رویکردهای پیشرفته است که به Q-learning منجر میشود.
الگوریتم یادگیری Q یک روش بدون مدل است که میتواند برای فرآیند تصمیمگیری مارکف قطعی و غیرقطعی اعمال شود. با مثالهایی مانند بهروزرسانی مقادیر Q، میتوان نحوه یادگیری عامل را مشاهده کرد.
اپیزودهای یادگیری، توالیهای تعامل عامل با محیط هستند و اثبات همگرایی این الگوریتمها تضمین میکند که به راهحل بهینه میرسند. یادگیری تفاوتهای زمانی (Temporal difference learning) و الگوریتم (TD(λ نیز از روشهای مهم در این حوزه هستند.
ترکیب شبکه عصبی با یادگیری Q به توانایی حل مسائل پیچیدهتر، از جمله سیستمهای بزرگ، کمک کرده، اما مسائل مطرح در یادگیری تقویتی همچنان نیازمند تحقیقات بیشتری هستند.