دانلود pdf مبانی کامپایلر کمیاب و عالی
مبانی کامپایلر از اساسی ترین مباحث در علوم کامپیوتر است که به فرایند ترجمه کدهای برنامه نویسی از یک زبان سطح بالا به زبان قابل فهم برای ماشین میپردازد. در واقع، کامپایلر یک برنامه سیستمی است که کدهای مبدأ را دریافت کرده و پس از انجام تحلیلهای مختلف، کدهای مقصد را تولید میکند.
این فرایند پیچیده به چندین اجزای کلیدی تقسیم میشود که هر یک وظیفه مشخصی را بر عهده دارند؛ از جمله این اجزا میتوان به تحلیلگر لغوی، تحلیلگر نحوی و تحلیلگر مفهومی اشاره کرد که هر کدام گامی اساسی در درک ساختار و معنای برنامه برمیدارند.
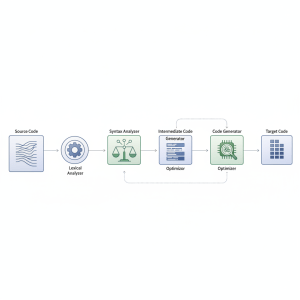
پس از مراحل تحلیل، نوبت به تولید و بهینهسازی کد میرسد. این بخش شامل مولد کد میانی است که یک نمایش مستقل از معماری تولید میکند. سپس بهینهساز کد میانی وارد عمل شده تا این کد را کارآمدتر سازد.
در نهایت، بهینهساز کد، کدهای نهایی را با هدف افزایش سرعت و کاهش حجم تولید میکند. همچنین، مفهوم کامپایلر کامپایلرها (یا مولدهای کامپایلر) نیز به عنوان ابزارهایی برای خودکارسازی ساخت کامپایلرها معرفی میشود.
نوع فایل: پی دی اف – 190 صفحه
فهرست مطالب:
- مبانی کامپایلر
- تعریف کامپایلر
- اجزای کامپایلر
- تحلیلگر لغوی
- تحلیلگر نحوی
- تحلیلگر مفهومی
- مولد کد میانی
- بهینه ساز کد میانی
- بهینه ساز کد
- کامپایلر کامپایلرها
- تحلیلگر لغوی
- مقدمه
- ساختار ورودی / خروجی
- عبارات با قاعده
- نمونههایی از عبارات با قاعده
- قوانین ایجاد عبارت باقاعده
- ماشین های خودکار
- ایجاد تابع تحلیلگر لغوی
- مساله عدم قطعیت
- رفع عدم قطعیت
- بهینه سازی ماشینهای خودکار
- تبدیل عبارات باقاعده به ماشینهای خودکار
- تمرین
- تجزیه بالا به پایین
- تحلیلگر ذهن
- ایجاد الگوریتم تحلیل نحوی بر مبنای عملکرد ذهن
- نتیجه تحلیل عملکرد ذهن
- گرامرهای LL(1)
- تبدیل گرامرها به فرم LL(1)
- فاکتور گیری چپ
- تبدیل قواعد خود بازگشتی چپ
- حذف قواعد تهی
- ایجاد جدول تجزیه بالا به پایین
- تجزیه گرهای کاهینه بازگشتی
- مولد تحلیلگر نحوی
- تمرین
- تجزیه پایین به بالا
- مقدمه
- اصول تجزیه پایین به بالا
- خلاصه عملیات در گراف تجزیه
- ایجاد جدول تجزیه
- مشکل گرامرهای LR(1)
- گرامرهای LALR(1)
- گرامرهای SLR(1)
- گرامرهای مبهم
- تولید کد میانی
- هدف
- انواع کدهای میانی
- روش تولید کد میانی
- تولید دستورالعملهای شبه اسمبلی برای عبارات چهار عمل اصلی
- تولید دستورالعملهای شبه اسمبلی برای انواع جملات
- جملات تخصیصی
- جملات شرطی
- تولید کد اسمبلی
- Register Management
- یک روش کلی (جایگذاری)
- مراحل
- دستورات متغیرهای محلی
- دستورات bipush، sipush و iinc
- دستورات پرش
- دستورات مربوط به کلاسها و اشیاء
- دستور newarray
- دستور multianewarray
- دستورات ldc و ldc_w
- دستور lookupswitch
- دستور tableswitch
- دستوراتی که هیچ عملوندی ندارند
- چگونه برنامهای به زبان Jasmin بنویسیم؟
- برنامه HelloWorld
- بررسی برنامه
- Initialization method
- Main method
- برنامه Count
- برنامه HelloWeb Applet
قیمت: 115/500 تومان
یکی از اولین مراحل در این زنجیره، تحلیلگر لغوی است که مسئول شناسایی واحدهای بنیادی زبان برنامه نویسی، یعنی واژهها یا توکنها، از جریان ورودی کاراکترها است. مباحث مربوط به تحلیلگر لغوی، بخش مهمی از مبانی کامپایلر را شامل میشوند.
مطالب مرتبط
- دانلود pdf اصول طراحی کامپایلر در 112 صفحه
این مرحله با مقدمهای بر چگونگی تعامل با ساختار ورودی و خروجی آغاز میشود و مفهوم عبارات با قاعده به عنوان ابزاری قدرتمند برای توصیف الگوهای لغوی مورد بررسی قرار میگیرد که اساس شناسایی توکنها را فراهم میآورد.
عبارات با قاعده با ارائه نمونههایی کاربردی و قوانین مشخص برای ایجادشان، چارچوبی محکم برای تعریف واژههای زبان ارائه میدهند. این عبارات سپس به ماشینهای خودکار تبدیل میشوند که مدلهای ریاضی برای تشخیص الگوها هستند.
ایجاد تابع تحلیلگر لغوی از طریق این ماشینها صورت میگیرد و چگونگی پردازش جریان ورودی و تولید توکنها را مشخص میکند.
در فرایند تحلیل لغوی، گاهی اوقات مسئله عدم قطعیت در شناسایی الگوها پیش میآید که روشهایی برای رفع آن مورد نیاز است. پس از رفع ابهامات، بهینهسازی ماشینهای خودکار برای افزایش کارایی و سرعت شناسایی توکنها اهمیت پیدا میکند.
تبدیل عبارات با قاعده به ماشینهای خودکار به صورت سیستمی انجام میشود تا این فرایند خودکارسازی شود. در کنار این مباحث، انجام تمرینهای متعدد به درک عمیقتر این اصول کمک شایانی میکند.
پس از تحلیل لغوی، نوبت به تجزیه بالا به پایین میرسد که یکی از رویکردهای اصلی در تحلیل نحوی است. در این روش، تحلیلگر تلاش میکند با شروع از نماد شروع گرامر، به ساختار نحوی برنامه دست یابد.
مفهوم “تحلیلگر ذهن” و ایجاد الگوریتم تحلیل نحوی بر مبنای عملکرد ذهن، بینش جالبی به این فرایند میدهد و به نتایج تحلیل عملکرد ذهن برای طراحی الگوریتمهای کارآمد منجر میشود. درک این رویکردها، هسته اصلی مبانی کامپایلر در زمینه تحلیل نحوی را تشکیل میدهد.
گرامرهای (۱)LL دستهای از گرامرها هستند که امکان تجزیه بالا به پایین بدون بازگشت به عقب را فراهم میکنند. برای استفاده از این گرامرها، اغلب نیاز به تبدیل گرامرها به فرم (۱)LL است.
این تبدیل شامل تکنیکهایی مانند فاکتورگیری چپ برای از بین بردن ابهامات گرامری و تبدیل قواعد خود بازگشتی چپ به فرمهای غیر بازگشتی است که به پیادهسازی سادهتر تحلیلگرها کمک میکند.
حذف قواعد تهی نیز گامی مهم در آماده سازی گرامرها برای تجزیه بالا به پایین است. پس از اصلاح گرامر، ایجاد جدول تجزیه بالا به پایین، تحلیلگر را قادر میسازد تا با یک نگاه به توکن بعدی، تصمیم درست را اتخاذ کند.
تجزیه گرهای کاهینه بازگشتی (recursive descent parsers) نیز روشی مستقیم برای پیاده سازی تجزیه کننده بالا به پایین هستند و ابزارهایی مانند مولد تحلیلگر نحوی (parser generators) این فرایند را خودکار میکنند. تمرینهای کاربردی در این زمینه، مهارتهای لازم برای طراحی و پیادهسازی این تحلیلگرها را تقویت میکنند.
در مقابل رویکرد بالا به پایین، تجزیه پایین به بالا قرار دارد که با شروع از توکنهای ورودی، به تدریج به سمت نماد شروع گرامر پیش میرود. مقدمهای بر اصول این روش، شامل خلاصه عملیات در گراف تجزیه، چگونگی ساختاردهی این فرایند را روشن میسازد.
ایجاد جدول تجزیه برای گرامرهای (۱)LR، (۱)LALR و (۱)SLR، چالشها و راه حلهای مرتبط با گرامرهای مبهم را پوشش میدهد و از بخشهای مهم مبانی کامپایلر در بحث تجزیه پایین به بالا محسوب میشود.
پس از تحلیل نحوی، مرحله تولید کد میانی آغاز میشود که هدف آن ایجاد یک نمایش مستقل از ماشین مقصد است. این کد میانی میتواند انواع مختلفی داشته باشد، مانند سه آدرسی یا درختهای نحوی انتزاعی.
روش تولید کد میانی برای عبارات چهار عمل اصلی و همچنین انواع جملات مانند جملات تخصیصی و جملات شرطی مورد بررسی قرار میگیرد تا ساختار کلی برنامه در قالب میانی بازنمایی شود. این مراحل پیشزمینه حیاتی برای درک کامل مبانی کامپایلر و تولید کد بهینه هستند.
مرحله نهایی در فرایند کامپایل، تولید کد اسمبلی (assembly code) است که به طور مستقیم برای پردازنده قابل اجراست. در این بخش، مدیریت ثباتها (Register Management) و تخصیص بهینه آنها برای افزایش کارایی کد از اهمیت بالایی برخوردار است.
یک روش کلی برای جایگذاری متغیرها در ثباتها و مراحل آن توضیح داده میشود. همچنین، دستوراتی مانند bipush، sipush، iinc برای متغیرهای محلی و دستورات پرش نیز معرفی میگردند.
برای تولید کد اسمبلی، به خصوص در محیطهای خاص مانند Jasmin (جاسمین) برای ماشین مجازی جاوا، با دستورات متنوعی روبرو میشویم. این دستورات شامل مواردی مربوط به کلاسها و اشیاء، مانند newarray و multianewarray برای آرایهها، ldc و ldc_w برای بارگذاری ثابتها، و دستورات کنترلی مانند lookupswitch و tableswitch هستند.
همچنین، دستوراتی که هیچ عملوندی ندارند نیز بخشی از این مجموعه را تشکیل میدهند. یادگیری چگونگی برنامهنویسی به زبان Jasmin با مثالهایی مانند برنامه HelloWorld، بررسی متد مقداردهی اولیه (Initialization method) و متد اصلی (Main method)، برنامه Count و برنامه اپلت HelloWeb (HelloWeb Applet) به همراه درک توصیفگرها (Descriptors) در ضمیمه یک، درک عمیقی از این مرحله ارائه میدهد.
در کنار مراحل تحلیل و تولید کد، تحلیل مفهومی (semantic analysis) نقش حیاتی در بررسی معنایی و منطقی برنامه ایفا میکند. این مرحله اطمینان حاصل میکند که برنامه از نظر نوع دادهها و استفاده از متغیرها صحیح است، حتی اگر از نظر نحوی درست باشد.
ضمیمه دوم، که به مولد کد Jasmin برای گرامر عبارات (Jasmin Code Generator for Expressions Grammar) میپردازد، ابزاری عملی برای درک چگونگی تبدیل ساختارهای نحوی به کد ماشین مجازی ارائه میدهد و تکمیل کننده بحث «مبانی کامپایلر» است.